
Personal Data in URLs

Parameters in the url (GET parameters) are used to pass information to the destination on the target server. Quite often I see cases where these GET parameters are used to transmit personal data. For example, a company sends out a newsletter to their clients with a link to their website where they want to personalize the content. In order to be able to render the right personalization, the personal data of the client is put in the url that links to the website, so these values can be picked up again by the script that renders the page. For example:
https://www.company.com/news/summer-deal.html?zipcode=12345&housenumber=35
In this post I’d like to discuss the consequences of this way of transmitting data. Because it is personal data, we also need to comply with privacy laws like the GDPR.
HTTP vs HTTPS
It’s a popular believe that even when a HTTPS url is used, the GET parameters in the url are not encrypted. So, let’s look at this from a man-in-the-middle¹ perspective and observe what we can see by looking at the url when we sniff the request with Wireshark.
The first screenshot is from a request sent over (plain) http:
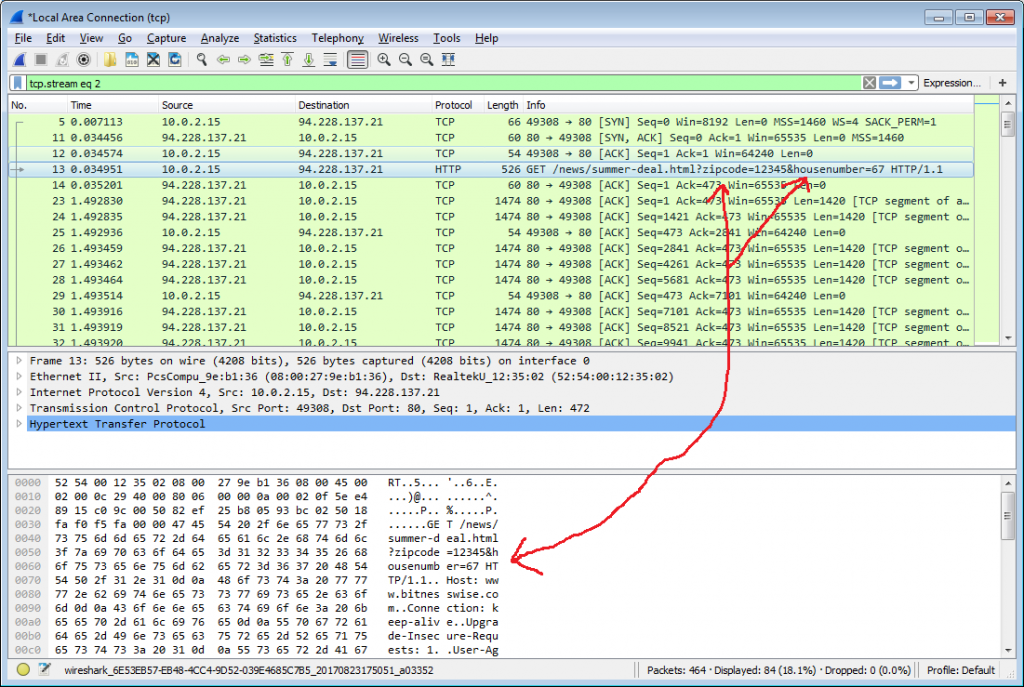
As you can see, the parameters are clearly visible for the man-in-the-middle.
And this is a screenshot of the same request sent over https:
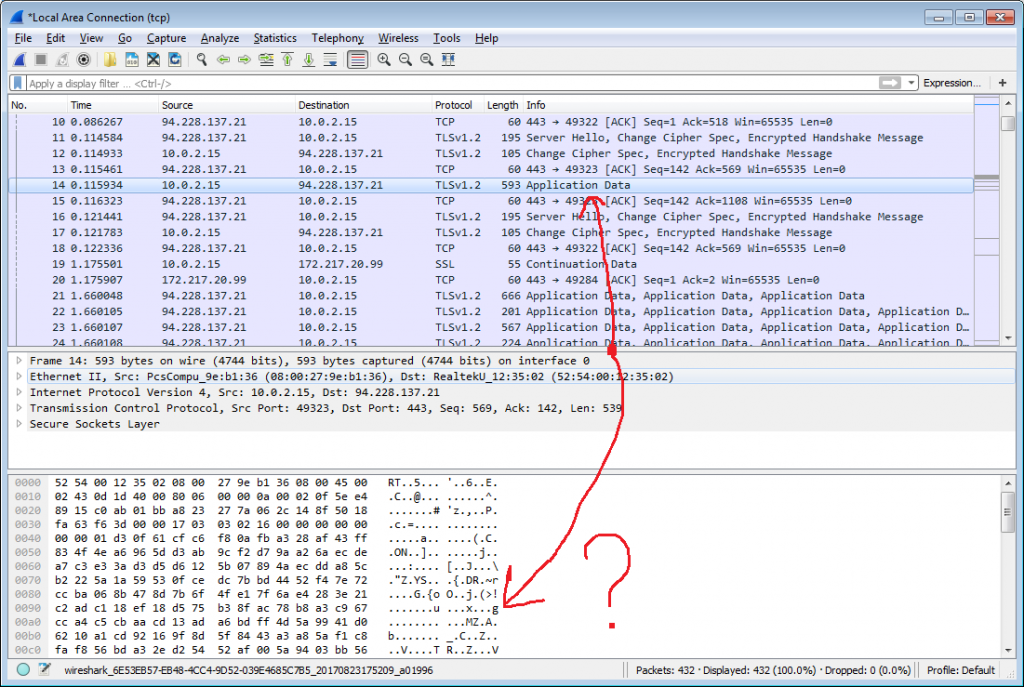
This time, the query parameters are not visible so you are safe from the man-in-the-middle (provided you’re using modern standards for the https connection).
However, there are other factors that have to be taken into account but that are often overlooked. I will go through them one by one and demonstrate why putting personal data in urls is not safe – even when HTTPS is used.
1. Webserver Logs
Requests – including the GET parameters – are often stored in the logs webservers. These logs might not be properly secured and retention times are often too high. And in the rare case that anonymization techniques are used (so they can be stored longer for statistical purposes), the GET parameters often still remain untouched (as they can form a vital part of the request which should be visible)
2. Browser History
Browsers keep a history of every page you visit, including all the GET parameters. This means the personal data will be stored unencrypted on the device that did the request.
3. Bookmarks
Urls might be bookmarked, which poses the same problem – meaning the data will be stored unencrypted on the device. In fact, popular bookmark applications will even sync them across different devices which makes the impact even higher than the previous point.
4. Printing
When printing a webpage, the url is often (by default) also printed.
5. Referrer Headers
Urls are passed in referrer headers². Although you can prevent this from happening by defining a Referrer Policy:
- The technique is fairly new and most websites don’t have it implemented yet.
- The policy might still change, misconfigurations might happen, etc, so you can’t rely on it yet.
- Most modern browsers support it, but there are still enough browsers in use that don’t. On top of that, browser support is not (yet) uniform.
6. Analytics Tools
The data might leak to third parties when an analytics tool has been implemented to record all the requests. This means that the url, including the GET parameters, is sent to the analytics company and now suddenly personal data is also stored by a third party.
Conclusion
Never put personal data in the url!
Having reached that conclusion, I feel I must present one exception. Suppose you are doing an asynchronous call from javascript (also known as ajax call), then most of the issues I addressed above are not applicable:
- Browser History: your browser doesn’t add it to the history
- Bookmarks: users won’t be able to bookmark it
- Printing: users won’t be able to print it either
- Referrer headers: because users don’t actually visit it, it will never show up in a referrer header
- Analytics: in principle, analytics tools won’t pick this up. Unless you’ve written a wrapper yourself for doing these kind of calls that will update the analytics backend, but in that case you know what you’re doing
Only one point remains: Webserver Logs. This still is an issue: if normal pages show up in the webserver logs, so will these requests. This is where you have to decide if that is a problem for you. If your webserver is like a fortress, access to the logs limited and the retention time set to a bare minimum, the risk of exposure is so limited that the effort it costs to mitigate the problem might be considered disproportional to the actual risk you run. It is not an exact science so that is something you have you to decide for yourself. But if you’re not sure then I would say it’s better to be safe than sorry.